Grammar
Tenses
Present

Present Simple
Present Continuous
Present Perfect
Present Perfect Continuous
Past
Past Simple
Past Continuous
Past Perfect
Past Perfect Continuous
Future
Future Simple
Future Continuous
Future Perfect
Future Perfect Continuous
Parts Of Speech
Nouns
Countable and uncountable nouns
Verbal nouns
Singular and Plural nouns
Proper nouns
Nouns gender
Nouns definition
Concrete nouns
Abstract nouns
Common nouns
Collective nouns
Definition Of Nouns
Animate and Inanimate nouns
Nouns
Verbs
Stative and dynamic verbs
Finite and nonfinite verbs
To be verbs
Transitive and intransitive verbs
Auxiliary verbs
Modal verbs
Regular and irregular verbs
Action verbs
Verbs
Adverbs
Relative adverbs
Interrogative adverbs
Adverbs of time
Adverbs of place
Adverbs of reason
Adverbs of quantity
Adverbs of manner
Adverbs of frequency
Adverbs of affirmation
Adverbs
Adjectives
Quantitative adjective
Proper adjective
Possessive adjective
Numeral adjective
Interrogative adjective
Distributive adjective
Descriptive adjective
Demonstrative adjective
Pronouns
Subject pronoun
Relative pronoun
Reflexive pronoun
Reciprocal pronoun
Possessive pronoun
Personal pronoun
Interrogative pronoun
Indefinite pronoun
Emphatic pronoun
Distributive pronoun
Demonstrative pronoun
Pronouns
Pre Position
Preposition by function
Time preposition
Reason preposition
Possession preposition
Place preposition
Phrases preposition
Origin preposition
Measure preposition
Direction preposition
Contrast preposition
Agent preposition
Preposition by construction
Simple preposition
Phrase preposition
Double preposition
Compound preposition
prepositions
Conjunctions
Subordinating conjunction
Correlative conjunction
Coordinating conjunction
Conjunctive adverbs
conjunctions
Interjections
Express calling interjection
Phrases
Sentences
Clauses
Part of Speech
Grammar Rules
Passive and Active
Preference
Requests and offers
wishes
Be used to
Some and any
Could have done
Describing people
Giving advices
Possession
Comparative and superlative
Giving Reason
Making Suggestions
Apologizing
Forming questions
Since and for
Directions
Obligation
Adverbials
invitation
Articles
Imaginary condition
Zero conditional
First conditional
Second conditional
Third conditional
Reported speech
Demonstratives
Determiners
Direct and Indirect speech
Linguistics
Phonetics
Phonology
Linguistics fields
Syntax
Morphology
Semantics
pragmatics
History
Writing
Grammar
Phonetics and Phonology
Semiotics
Reading Comprehension
Elementary
Intermediate
Advanced
Teaching Methods
Teaching Strategies
Assessment

A text-based account
 المؤلف:
Ingo Plag
المؤلف:
Ingo Plag
 المصدر:
Morphological Productivity
المصدر:
Morphological Productivity
 الجزء والصفحة:
P106-C5
الجزء والصفحة:
P106-C5
 2025-01-18
2025-01-18
 1099
1099




+
-
20
A text-based account
For computing the productivity measures proposed by Baayen I chose the Cobuild corpus, which has been developed and used extensively for a number of dictionary projects (e.g. the COBUILD dictionary 1987, see Sinclair 1987 for an account of the development and use of the corpus). The Cobuild corpus is an on-line available sample of a much larger corpus, the so-called Bank of English. Both the full and the sample corpus are constantly enlarged and updated, so that, unfortunately, it is impossible to make reference to a particular version of the Cobuild corpus. I have mainly worked with the complete tagged1 word list that I extracted in July 1995, when the Cobuild corpus had reached the size of c. 20 million words. The tagged word list contains all word forms (tokens) and their frequencies as they are found in the July 1995 corpus. This particular version of the corpus is archived with CobuildDirect and was re-accessed in September/October 1996 for the checking of problematic items.2 By that time, the regular Cobuild corpus had already increased in size to c. 50 million words.
In view of the uncontroversial unproductivity of eN-, -en, and be-, and the impossibility to search for zero-derived verbs, I limited my attention to the only three productive ones, -ize, -ate and -ify.
From the complete Cobuild word list all forms were extracted that contained the strings of letters that may represent the three suffixes -ize, -ate, and -ify. To extract all -ize formations, for example, I searched the complete word list for words ending in the strings, using the TACT® text retrieval program. The resulting lists still contained a large amount of data that were either irrelevant or problematic. Whereas obviously useless data (such as bodywise or Diana-gate) were fairly easily eliminated, the treatment of the problematic forms proved extremely difficult.
For the calculation of Ρ (and the other measures) it is necessary to count all words with a given affix in the corpus. The problematic task is now to decide which words can be considered to bear the affix in question, i.e. to determine which strings of letters represent the relevant verbal suffix. What looks like a straightforward procedure with an affix like -ness proved to be extremely difficult with words in -ate and, to a much lesser extent, -ize and -ify. The problems include the following.
The verbal suffixes under discussion appear to be semantically diverse and many of their derivatives are semantically or phonologically opaque. The semantically diverse affixes pose the question as to whether they really represent a single morpheme or a number of different, homophonous ones. Furthermore, there are derivatives that are not based on existing words but on bound roots. Thus it could be argued that forms like baptize or propagate are morphologically simplex, since they are not derived by the suffixation of -ize or -ate to an already existing base word. However, independent of the theoretical approach taken, there is an undeniable non-arbitrary connection of these two derivatives to other words featuring -ize and -ate, in that the two strings at least indicate the verbal status of the word. Thus, even in opaque formations one could argue for the presence of a suffix which indicates the verbal category of the word, if nothing else. This problem becomes even more complicated when we take into consideration that many -ate verbs that look perfectly transparent are actually analogical formations or back-formations, and not derived by the suffixation of -ate to a given word.
Even if it were possible to neatly separate transparent from opaque formations, the exclusion of non-transparent forms from the sampling would possibly lead to an overly high productivity measure, obliterating the effect that non-transparent items have on the overall productivity of a process. A high proportion of many non-transparent types (with usually higher token-frequency) are indicative of less productive processes. Hence, the exclusion of opaque forms would lead to a higher productivity value Ρ than one would probably want to have. From a structural viewpoint the semantic opacity and diversity of a large number of derivatives is also indicative of less productive processes (cf. van Marie 1988). The exclusion of opaque formations would therefore artificially clean up the messy state the process is actually in.
It was therefore decided to leave all opaque words in the list, as long as a suffix could be identified that indicated the verbal status of the word. On the basis of this criterion, baptize and propagate were included, because of the existence of, for example, baptism and propaganda. However, one has to be aware that, on this policy, the existence of a potentially large number of old, lexicalized, non-transparent words may negatively influence the productivity measure.3
Another important problem concerning the sampling of derived verbs lies in multiple affixation. In combinations of -ize with -able (as in conventionalizable) the question arises whether such words should be counted as -able derivatives, or as -ize derivatives, or both? For the researcher, it seems reasonable to partition the lexicon into disjunct classes in order to be able to compare measures across affixes. According to this rationale, only the affix that has been attached last is counted, i.e. in the case of our example conventionalizable we would assign the word exclusively to the category of -able derivatives. Although not mentioned in his publications, this policy has been confirmed by Baayen (personal communication, October 1996).
However, psycholinguistically this partitioning of the lexicon does not seem to be completely adequate because speakers do not only parse the outmost suffix. A speaker who has never come across conventionalize will probably still note that this (potential) word is contained in the new word conventionalizable, and this information will somehow add to the speaker's knowledge of possible -ize formations. Baayen's measures therefore cannot reflect the influence multiply affixed words may have on the representation of the inner affixes occurring in such derivatives. In essence, the decision to exclude tokens with inner affixes of the relevant category from the count is largely dictated by practical considerations at the cost of the psycholinguistic value of the measures. This somewhat weakens Baayen's claim that his measures are psycholinguistically well-founded.
The treatment of multiple affixation is especially problematic with the verbal suffixes under discussion because they are often followed by inflectional elements. The most obvious treatment would be to ignore inflectional endings altogether because they have no bearing on the issue of derivational productivity. However, the participial suffixes -ing and -ed. could be argued to derive adjectives or nouns from the verbal stem. It is therefore not obvious whether a participle like conventionalizing, which can surface as an adjective or as a noun, should in this case be counted as an instance of a derivational suffix -ing or of a derivational suffix -ize. The problem of the syntactic category of participial forms is notorious and will not be discussed in detail here.4 I have settled for a count that treats the participial endings as purely inflectional, hence treating the relevant forms as verbs inspite of their possible occurrence in the syntactic positions of nouns or adjectives.
This problem is further complicated by the fact that the tagging in the Cobuild corpus is often incorrect, with the consequence that many of the nominally and adjectivally tagged words in question are in fact clearly verbs (the reverse seems to be less frequent).5 According to a rough estimate, about ten percent of all relevant tokens are adjectivally or nominally tagged.
In sum, I decided to ignore all inflectional endings and count not only the verbally tagged tokens but also the nominally and adjectivally tagged ones. Unfortunately, some more problems emerged with -ate. While it was still relatively easy to deal with verbs such as create and debate, which were eliminated on the basis that they have primary stress on <ate>, a major problem occurred with forms that have adjectival or nominal homographs. For instance, discriminate can be a verb or an adjective, estimate can be a verb or a noun. The only way to overcome, if not solve, this dilemma was to use the tagging, in spite of its potential error-proneness.6 Hence, of all types in -ate on the list that were ambiguous between the adjectival, nominal and verbal interpretation only those tokens were counted that were tagged as verbs. Thus, all homographs tagged as adjectives or nouns were excluded from the calculation. For illustration, consider alternate, which entered the list of -ate derivatives with an overall number of 89 verbally tagged tokens, whereas the 70 adjectivally and nominally tagged tokens were erased from the list.
Note that by excluding the nominally and adjectivally tagged tokens of ambiguous -ate words I treated -ate derivatives in a manner slightly different from -ize and -ify words. Thus the exclusion of the adjectivally and nominally tagged tokens that are homophonous with -ate verbs may have led to the exclusion of some tokens of participles of -ate verbs which the tagging program has tagged as adjectival or nominal. This distortion seemed negligible in comparison to the alternative, namely counting only the verbally tagged items for all suffixes, which would have been theoretically less preferable and practically would have meant an even greater reliance on possibly wrong taggings.
Another alternative option would have been to include even the homographic adjectival and nominal -ate forms. As shown in table 1 below, -ate is the least productive suffix (in terms of P), even under the exclusion of the homographie adjectival and nominal forms. The inclusion of these forms would only have increased the overall number of -ate tokens, without significantly raising the number of hapaxes. In other words, the inclusion of the homographie adjectival and nominal forms would have only led to a further decrease in P. In view of these considerations the policy chosen seemed to be the best of all available ones.
Before we turn to the results of our investigation, a note of caution is in order. The foregoing discussion of the intricacies of the sampling method has made clear that the procedure adopted here is only one out of a whole range of possible others. Different methodological decisions could be justified, leading perhaps to different results. Possible effects of the sampling method on the results are occasionally mentioned below, but a more systematic investigation of such effects is certainly called for. This will be left to future studies, however, since we are more concerned with the structural than with the quantitative aspects of productivity. In view of the methodological problems, the importance of the results given below should not be overestimated.
Performing the procedures just outlined, I arrived at the following figures:
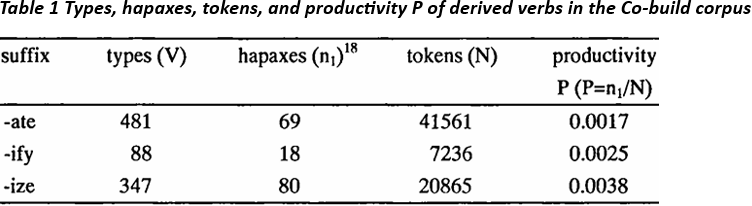
hapaxes (n1) 7
We will discuss the three central productivity measures, namely the number of forms with a given affix ('extent of use' V ), the probability of encountering new formations ('productivity in the narrow sense' P), and the number of new formations in a given corpus or period ('global productivity' P*), which is indicated by the number of hapaxes (n1). We will not discuss the degree of exhaustion ('pragmatic potentiality' I), since its value is rather questionable.
The following picture emerges from table 1 The suffix -ate has the highest extent of use V, followed closely by -ize, whereas -ify occurs in much fewer types. However, -ate is clearly the least productive in the narrow sense, since in relation to its extremely high number of tokens (N=41561) there are very few hapaxes, i.e. new types. The suffix -ate can therefore be characterized as a suffix that occurs in many different existing words, but which is not used very often to coin new verbs.
By far the most productive process in the narrow sense is -ize, which occurs in almost as many different types as -ate, but gives rise to many more new words in relation to the overall number of tokens. Thus the probability of encountering a neologism among all -ize derivatives is much greater than with -ate verbs. The suffix -ify occupies the medial position in terms of P, although only few existing verbs contain this suffix, i.e. V and n1 are low.
A qualitative look at the hapaxes corroborates these results. Most of the hapaxes featuring -ify and -ize are phonologically and semantically transparent, which indicates their status as productive formations. The majority of them are either not listed at all in the OED or are listed there as twentieth century innovations, which results in a considerable overlap of forms in the list of OED neologisms and the list of Cobuild hapaxes (see appendices 1 and 2). Hence the qualitative analysis of the -ize and -ify hapaxes gives evidence for the productivity of these suffixes. The hapaxes involving -ate, however, are in their majority words that are not transparent neologisms, but simply rare words or rather strange innovations, a fact that is indicative of the low productivity of the process. Let us pick out randomly the alphabetically first 10 -ate hapaxes for illustration. Of these, seven are rather old words (acidulate 1732, agglomerate 1684, agglutinate 1586, annuate 1623, apostemate 1582, contemplate 1605, concatenate 15988), only two forms seem to be genuine productive formations (caffeinate, cavitate), and one has remained opaque even after the consultation of a number of different dictionaries (calvulate). This qualitative look at the data reveals that the use of hapaxes as indicators of productivity is not generally justified. Whereas with more productive suffixes like -ness, -ize and -ify the proportion of real neologisms among the hapaxes is rather high, this is not the case with -ate.9 This casts a shadow over the rationale of Baayen's productivity measures Ρ and P*, for it seems that the proportion of neologisms among the hapaxes can vary a great deal between different word formation rules. Hence, the -ate derivatives in the Cobuild corpus run counter to the general trend that low-frequency items are semantically transparent, as argued, for example, by Baayen and Lieber (1997).
The low productivity Ρ of -ate could, however, also be seen as an artefact of our sampling procedure because all opaque formations were included, which has increased the number of all tokens, leading to a low measure P. However, the exclusion of opaque formations would have resulted in a rather drastic decline of the number of hapaxes and the number of different types, thereby negatively influencing these productivity measures. Thus it seems that including only the transparent formations would at best upgrade P, but further downgrade P* and V.
It is interesting to briefly compare the results for derived verbs with those obtained by Baayen and Renouf (1996) concerning other derivational affixes (they consider -ity, -ness, -ly10, un-, in-). The figures for types (V) and hapaxes (n1) of these affixes can be taken from Baayen and Renouf (1996:74), but the numbers of tokens are not given in this article. However, Harald Baayen kindly provided me with the relevant figures (personal communication, July 1997). Consider the following table:
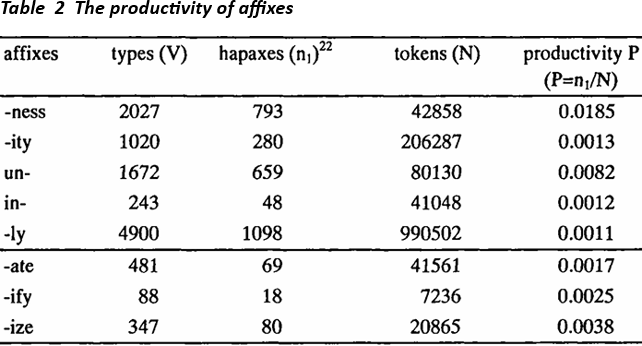
hapaxes (n1) 11
Types, hapaxes, tokens, and productivity Ρ of different affixes in the Times corpus (Baayen and Renouf 1996, Baayen p.c., July 1997), compared with verbal suffixes in the Cobuild corpus
Let us start with a comparison of global productivity. The number of hapaxes observed for the derived verbs are much smaller than those of extremely productive affixes like -ness and un-, let alone -ly. For example, in the 80 million word Times corpus Baayen and Renouf find 739 and 659 hapaxes for -ness and un-. Assuming an equal distribution of the hapaxes across the corpus, which seems justified for the purposes of a rough comparison (cf. figure 3 in Baayen and Renouf 1996:77), we can divide these figures by 4 in order to arrive at comparable numbers of hapaxes (recall that the Cobuild corpus was 20 million words). Thus we end up with calculated 180 and 165 hapaxes of -ness and un-, respectively, as against 80, 69, and 18 for -ize, -ate, and -ify. Although there is still a big difference between the two sets, we have to keep in mind that the overall productivity of verbs is very low in comparison to adjectives and, especially, nouns (e.g. Baayen and Lieber 1991). What emerges from this comparison of hapaxes is that at least -ize and -ate reach a reasonable degree of global productivity, whereas the global productivity of -ify is indeed low.
A comparison of the productivity in the narrow sense reveals that the verbal suffixes lie between the comparatively unproductive -ity and in- on the one hand, and the highly productive affixes -ness and un-. What is perhaps more surprising is the fact that the value of Ρ for adjectival and adverbial -ly is lower than that of any of the verbal suffixes. This low value of Ρ is not mentioned in Baayen and Renouf but certainly needs some explanation in view of the high global productivity of this suffix. This discrepancy between the different measures shows that one should not rely on one measure alone, because each measure highlights different aspects of productivity. The number of hapaxes for -ly indicates that there is a high probability to encounter new -ly forms as the corpus increases.12 The productivity in the narrow sense for -ly, however, is very low because there are so many tokens of this category that there is a small chance to encounter new formations among them. Ignoring possible differences concerning the text types exemplified in the two corpora, we can summarize this brief comparison by saying that the verbal suffixes under discussion are reasonably productive, but certainly not as productive as affixes like un- or -ness which seem to be subject to little restrictions.
Before we finally compare the dictionary-based analysis with the text corpus analysis, a word is in order concerning earlier calculations on the basis of the CELEX corpus. As already discussed in some detail, the CELEX corpus is based on the original Cobuild corpus (c. 18 million words) but is inaccurate in representing low-frequency items, which in turn negatively influences the calculation of the productivity measures. The figures in table 1 now enable us to show the extent to which the CELEX-based figures given by Baayen and Lieber (1991) are false. These authors arrive at only 102 overall types (V) for -ize and 50 types for -ify, with P=0.0000 for -ify, and P=0.0001 and P=0.0002 for deadjectival and denominal -ize, respectively {-ate is not considered). Even if we take into consideration that the July 1995 Cobuild corpus is roughly 10% larger than the Cobuild corpus used for the CELEX database, the huge discrepancies are still obvious. In view of the differences between the original Cobuild figures and the distorted CELEX figures all conclusions on the basis of the CELEX figures are disposable.
1 The following tags from the word list are relevant here: NN (common singular noun), NNS (common plural noun), JJ (adjective), VB (verb base form), VBD (verb past tense form), VBN (verb participle form), VBZ (verb 3rd person singular), VBG (verb -ING form).
2 I would like to thank the CobuildDirect staff, especially Jeremy Clear, for their assistance.
3 Note again that this kind of problem practically does not occur with processes like -ness suffixation, which is indeed one of the reasons why Baayen and Re nouf (1996) chose this suffix for investigation, among others (Baayen, personal communication, July 1997). Unfortunately they do not reveal their policy concerning the sampling of -ity words, which, similar to the verbal suffixes, is also often found in lexicalized forms.
4 See, for example, Haspelmath (1996) for a recent account of category-changing inflection.
5 The high error rate in the tagging, acknowledged by CobuildDirect, is due to the fact that the tagging is done automatically by a computer program.
6 The other possible alternative would have been to double-check all pertinent tokens with their context on-line in the corpus, which was decided against for practical reasons. Presumably, the distorting effect by wrongly tagged items is not significant, so that the probably slightly more accurate result would not have justified the enormous costs (in terms of money and effort) of the investigation.
7 The hapaxes are listed in appendix 2. AH hapaxes were checked against the original corpus. On the basis of this check, a number of hapaxes as they occur in the Cobuild word list had to be eliminated as incorrect spellings.
8 The dates given are early attestations as given by the OED.
9 Interestingly, Baayen and Renouf (1996:86) mention the same unexpected behavior with the negative prefix in-. Thus, many hapaxes in in- are well established technical terms like incompetence that just "happen not to enjoy a high frequency in the Times". They try to make a virtue out of the vice of their methodology by claiming that the small number of overall hapaxes and the fact that less than half of the hapaxes are innovations indicates that in- is hardly productive. However, they do not discuss the fact that such ill-behaved affixes are problematic with regard to quantitative measurements.
10 The status of adverbial -ly as a derivational suffix is controversial. Whereas Bauer (1983:225) treats it as derivational, Marchand (1969) obviously takes a different position, since he only describes adjectival -ly and does not mention adverbial -ly at all. I am also inclined to classify -ly as an inflectional suffix. For our discussion this issue is irrelevant.
11 The hapaxes are listed in appendix 2. All hapaxes were checked against the original corpus. On the basis of this check, a number of hapaxes as they occur in the Cobuild word list had to be eliminated as incorrect spellings.
12 For instance, in the last month of sampling, Baayen and Renouf find 40 new words in -ly, 29 in -ness, 25 in un-, 11 in -ity, and none in in-.
 الاكثر قراءة في Morphology
الاكثر قراءة في Morphology
 اخر الاخبار
اخر الاخبار
اخبار العتبة العباسية المقدسة

الآخبار الصحية


مواضيع ذات صلة
 قسم الشؤون الفكرية يصدر كتاباً يوثق تاريخ السدانة في العتبة العباسية المقدسة
قسم الشؤون الفكرية يصدر كتاباً يوثق تاريخ السدانة في العتبة العباسية المقدسة "المهمة".. إصدار قصصي يوثّق القصص الفائزة في مسابقة فتوى الدفاع المقدسة للقصة القصيرة
"المهمة".. إصدار قصصي يوثّق القصص الفائزة في مسابقة فتوى الدفاع المقدسة للقصة القصيرة (نوافذ).. إصدار أدبي يوثق القصص الفائزة في مسابقة الإمام العسكري (عليه السلام)
(نوافذ).. إصدار أدبي يوثق القصص الفائزة في مسابقة الإمام العسكري (عليه السلام)