Grammar
Tenses
Present

Present Simple
Present Continuous
Present Perfect
Present Perfect Continuous
Past
Past Simple
Past Continuous
Past Perfect
Past Perfect Continuous
Future
Future Simple
Future Continuous
Future Perfect
Future Perfect Continuous
Parts Of Speech
Nouns
Countable and uncountable nouns
Verbal nouns
Singular and Plural nouns
Proper nouns
Nouns gender
Nouns definition
Concrete nouns
Abstract nouns
Common nouns
Collective nouns
Definition Of Nouns
Animate and Inanimate nouns
Nouns
Verbs
Stative and dynamic verbs
Finite and nonfinite verbs
To be verbs
Transitive and intransitive verbs
Auxiliary verbs
Modal verbs
Regular and irregular verbs
Action verbs
Verbs
Adverbs
Relative adverbs
Interrogative adverbs
Adverbs of time
Adverbs of place
Adverbs of reason
Adverbs of quantity
Adverbs of manner
Adverbs of frequency
Adverbs of affirmation
Adverbs
Adjectives
Quantitative adjective
Proper adjective
Possessive adjective
Numeral adjective
Interrogative adjective
Distributive adjective
Descriptive adjective
Demonstrative adjective
Pronouns
Subject pronoun
Relative pronoun
Reflexive pronoun
Reciprocal pronoun
Possessive pronoun
Personal pronoun
Interrogative pronoun
Indefinite pronoun
Emphatic pronoun
Distributive pronoun
Demonstrative pronoun
Pronouns
Pre Position
Preposition by function
Time preposition
Reason preposition
Possession preposition
Place preposition
Phrases preposition
Origin preposition
Measure preposition
Direction preposition
Contrast preposition
Agent preposition
Preposition by construction
Simple preposition
Phrase preposition
Double preposition
Compound preposition
prepositions
Conjunctions
Subordinating conjunction
Correlative conjunction
Coordinating conjunction
Conjunctive adverbs
conjunctions
Interjections
Express calling interjection
Phrases
Sentences
Clauses
Part of Speech
Grammar Rules
Passive and Active
Preference
Requests and offers
wishes
Be used to
Some and any
Could have done
Describing people
Giving advices
Possession
Comparative and superlative
Giving Reason
Making Suggestions
Apologizing
Forming questions
Since and for
Directions
Obligation
Adverbials
invitation
Articles
Imaginary condition
Zero conditional
First conditional
Second conditional
Third conditional
Reported speech
Demonstratives
Determiners
Direct and Indirect speech
Linguistics
Phonetics
Phonology
Linguistics fields
Syntax
Morphology
Semantics
pragmatics
History
Writing
Grammar
Phonetics and Phonology
Semiotics
Reading Comprehension
Elementary
Intermediate
Advanced
Teaching Methods
Teaching Strategies
Assessment

Empirical methods in the study of semantics
 المؤلف:
GEORGE A. MILLER
المؤلف:
GEORGE A. MILLER
 المصدر:
Semantics AN INTERDISCIPLINARY READER IN PHILOSOPHY, LINGUISTICS AND PSYCHOLOGY
المصدر:
Semantics AN INTERDISCIPLINARY READER IN PHILOSOPHY, LINGUISTICS AND PSYCHOLOGY
 الجزء والصفحة:
569-32
الجزء والصفحة:
569-32
 2024-08-26
2024-08-26
 1609
1609




+
-
20
Empirical methods in the study of semantics1
Methodology, the bread-and-butter of a scientist working in any given field, is usually spinach to those outside. I will try to keep my methodological remarks as brief as possible.
We now have some notion of what a theory of the interpretation of sentences might look like, and some glimmerings of the kind of lexical information about constituent elements that would be required. It is quite difficult, however, to launch directly into the compilation of a lexicon along the lines suggested by this theory; so many apparently arbitrary decisions are involved that it becomes advisable to try to verify them somehow as we go. One important kind of verification, of course, is given by a theorist’s own intuitions as a native speaker of the language; such intuition is probably the ultimate court of appeal in any case. But, if possible, it would be highly desirable to have some more objective method for tapping the intuition of language users, especially if many people could pool their opinions and if information about many different words could be collected and analyzed rapidly. A number of efforts have been made to devise such methods.
As far as I am aware, however, no objective methods for the direct appraisal of semantic contents have yet been devised, either by linguists or psychologists. What has been done instead is to investigate the semantic distances that are implied by the kind of spatial and semispatial representations we have just reviewed. The hope is that from a measurement of the distances between concepts we can infer something about the coordinates of their universe. Distance can be related to similarity, and judgments of similarity of meaning are relatively easy to get and to analyze. Several methods are available.
The empirical problem is this. It is not difficult to devise ways to estimate semantic similarities among words. On the basis of such judgments of similarity we would like to construct, or at least test, theoretical descriptive schemes of the sort just reviewed. Any large-scale empirical attack on the problem would involve three steps:
(1) Devise an appropriate method to estimate semantic similarities and use it to obtain data from many judges about a large sample of lexical items. These data form a symmetric items-by-items matrix, where each cell aij is a measure of the semantic similarity between item i and j.
(2) Devise an appropriate method to explore the structure underlying the data matrix. Among the analytic tools already available, factor analysis has been most frequently used, but various alternatives are available. In my research I have used a method of cluster analysis that seems to work rather well, but improvements would be possible if we had a solid theoretical basis for preferring one kind of representation over all others.
(3) Identify the factors or clusters in terms of the concepts in a semantic theory. In most cases, this is merely a matter of finding appropriate names for the factors or clusters. Given the backward state of semantic theory at present, however, this step is almost not worth taking. Eventually, of course, we would hope to have semantic descriptions, in terms of marker or list structures, say, from which we could not only construct sentence interpretations, but could also predict similarity data for any set of lexical items. At present, however, we have not reached that stage of sophistication.
Most of the energy that psychologists have invested in this problem so far has gone into step (1), the development of methods to measure semantic similarity. However, since there is no generally accepted method of analysis or established theory against which to validate such measures, it is not easy to see why one method of data collection should be preferred over the others. But, in spite of the sometimes vicious circularity of this situation, I think we are slowly making some headway toward meaningful methods.
There are four general methods that psychologists have used to investigate similarities among semantic atoms: (1) scaling, (2) association, (3) substitution, and (4) classification. I myself have worked primarily with classification, but I should mention briefly what alternative procedures are available. Where possible, examples of the methods will be cited, but no attempt at a thorough review is contemplated.
(1) The method of subjective known as magnitude estimation, as described by S. S. Stevens in numerous publications, suggests itself as a simple and direct method to obtain a matrix of semantic similarity scores. So far as I know, this method has not been used in any systematic search for semantic features.
Scaling methods have been used in psychometric research. Mosier used ratings to scale evaluative adjectives along a favorable-unfavorable continuum, and Cliff used them to argue that adverbs of degree act as multipliers for the adjectives they modify. However, these studies did not attempt to construct a general matrix of similarity measures for a large sample of the lexicon, or to discover new semantic features.
One example of the use of scaling is a study reported by Rubenstein and Good- enough. They asked people to rate pairs of nouns for their ‘ similarity of meaning ’. They used a five-point scale, where zero indicated the lowest degree of synonymy and four the highest. Their averaged results for 65 pairs of words included the following:

Although Rubenstein and Goodenough did not obtain a complete matrix of all comparisons among the 48 words they used, their results indicate that meaningful estimates can be obtained by this technique.
A difficulty that any procedure must face is that a truly enormous amount of data is required. If a lexicon is to contain, say, 106 word senses, then the similarity matrix with have 1012 cells to be filled. It is obvious immediately that any empirical approach must settle for judgments on strategic groups of word items selected from the total lexicon. But even with that necessary restriction, the problem is difficult. If, for example, we decide to work with 100 items in some particular investigation, there are still 4950 pairs that have to be judged. If we want several judges to do the task, and each judge to replicate his data several times, the magnitude of the data collection process becomes truly imposing. It is doubtful that judges could maintain their interest in the task for the necessary period of time. If a multidimensional scaling procedure is used in which judges decide which two of three items are most similar, the number of judgments required is even greater: 100 items give 161,700 triplets to be judged.
For this reason, scaling procedures do not seem feasible for any large survey of semantic items; preference must be given to methods that confront a judge with the items one at a time, where similarity is estimated on the basis of the similarities of his responses to the individual items - thus avoiding the data explosion that occurs when he must judge all possible pairs, or all possible triplets. Scaling methods should probably be reserved for those cases where we want a particularly accurate study of a relatively small number of items.
(2) Because of the historical importance of association in philosophical theories of psychology, more work on semantic similarity has been done with associative methods than with any other. This work has been reviewed by Creelman and also by Deese, who made it the starting point for a general investigation of what he calls ‘associative meaning ’.
In the most familiar form of the associative method, people are asked to say (or write) the first word they think of when they hear (or read) a particular stimulus word. When given to a large group of people, the results can be tabulated in the form of a frequency distribution, starting with the most common response and proceeding down to those idiosyncratic responses given by only a single person. Then the similarity of two stimulus words is estimated by observing the degree to which their response distributions coincide.
The procedure for estimating the degree of similarity from two response distributions is a very general one that has been used in one form or another by many workers. The logic behind it is to express the measure of similarity as a ratio of some measure of the intersection to some measure of the union of the two distributions. In the case of word associations, the responses to one word constitute one set, the responses to another word another. The intersection of these two sets consists of all responses that are common to the two; the union is generally interpreted to be the maximum number of common responses that could have occurred. The resulting ratio is thus a number between zero and one.
The argument is sufficiently general that intersection-union ratios can be used in many situations other than word association tests; their use in studies of information retrieval, where synonymy must be exploited to retrieve all documents relevant to a given request, has been reviewed by Giuliano and Jones and by Kuhns. The ratio has been invented independently by various workers, for in one version or another it is the natural thing to do when faced with data of this type. Consequently, it has been given different names in different context - intersection coefficient, coefficient of association, overlap measure, etc. - and minor details of definition and calculation have occasionally been explored, though rather inconclusively.
The utility of an intersection-union ratio is that estimates of similarity can be obtained without actually presenting all possible pairs to the judges. The assumption underlying it, of course, is that similarity of response reflects similarity of meaning. If, as some psychologists have argued, the meaning of any stimulus is all the responses it evokes, this argument is plausible. But the notion that the meaning of a word is all the other words it makes you think of should not be accepted without some reservations.
The principal recommendation for a word association technique is its convenience of administration; it is generally given in written form to large groups of subjects simultaneously. The method gives some information about semantic features, since an associated word frequently shares several semantic features of the presented word, but it is also sensitive to syntactic and phonological association. Attempts have been made to classify associates as either syntagmatic or paradigmatic, but the results have been equivocal, e.g., if storm elicits cloud, or flower elicits garden, is the response to be attributed to paradigmatic semantic similarity or to a familiar sequential construction? The method is sensitive only to high degrees of similarity in meaning; most pairs of the words elicit no shared responses at all. And no account is taken of the different senses that a word can have; when, for example, fly is associated with bird and also with bug, we suspect that fly has been given in different senses by different people, but the data provide no way to separate them.
A variation on the association technique that combines it with the scaling methods has been developed and extensively used by Osgood, who constrains a judge’s response to one or the other of two antonymous adjectives. Several pairs of adjectives are used and people are allowed to scale the strength of their response. By constraining the judge’s responses to one of two alternatives Osgood obtains for all his stimulus words distributions of responses that are sufficiently similar that he can correlate them, even for words quite unrelated in meaning. When these correlations are subjected to factor analysis, a three-dimensional space is generally obtained. The position of all the stimulus words can be plotted in a three-dimensional space defined by the antonymous adjectives. It is not clear that these three dimensions bear any simple relation to semantic markers - nor does Osgood claim they should. It is true that words near one another in the space often share certain semantic features, but the method gives little hint as to what those shared features might be. Osgood’s method is most useful for analyzing attitudinal factors associated with a word.
(3) Another approach uses substitution as the test for semantic similarity. In linguistics a technique has been developed called ‘distributional analysis’. The distributional method has been most highly developed in the work of Zelig Harris.
Consider all the words that can be substituted in a given context, and all the con¬ texts in which a given word can be substituted. A linguist defines the distribution of a word as the list of contexts into which the word can be substituted; the distributional similarity of two words is thus the extent to which they can be substituted into the same contexts. One could equally well consider the distributional similarity of two contexts. Here again an intersection-union ratio of the two sets can provide a useful measure of similarity.
Closely related to distributional similarity is a measure based on co-occurrence. Co-occurrence means that the words appear together in some corpus, where ‘ appear together’ may be defined in various ways, e.g., both words occur in the same sentence. We can, if we prefer, think of one word as providing the context for the other, thus making the distributional aspect explicit. A union-intersection measure of similarity can be defined by taking as the intersection the number of times the words actually co-occurred, and as the union the maximum number of times they could have co-occurred, i.e., the number of times the less frequent word was used in the corpus. Co-occurrence measures have the advantage that they can be carried out automatically by a properly programmed computer. Distributional measures can in general be made automatic if a very large corpus is available - large enough that the two words will recur many times.
Several psychologists have invented or adapted variations on this distributional theme as an empirical method for investigating semantic similarities. It is, of course, the basis for various sentence completion procedures insofar as these are used for semantic analysis. The basic assumption on which the method rests is that words with similar meanings will enjoy the same privileges of occurrence, i.e., will be substitutable in a great variety of contexts.
For example, couch and sofa can be substituted interchangeably in a great variety of contexts, and they are obviously closely related in meaning. In terms of a theory of semantic markers, some such relation would be expected, since the semantic features of the words in any meaningful sentence are interdependent. The predicate is upholstered imposes certain restrictions on the semantic markers of its subject, and only words that have those required features can be substituted as subject without violently altering the acceptability of the sentence. Couch, sofa, chair, etc., are substitutable in the context The. . .is upholstered, and are similar in meaning, whereas sugar, hate, learn, delicate, rapidly, etc., are not. If the method is used blindly, of course, it can lead to absurd results, e.g., no and elementary are not similar in meaning just because they can both be substituted into the frame John has studied. . . psychology.
If judges are asked to say whether or not two items are substitutable in a given context, they must be instructed as to what is to remain, invariant under the substitution. Various criteria can be applied: grammaticality, truth, plausibility, etc. The results can be very different with different criteria. If meaning is to be preserved, for example, only rather close synonyms will be acceptable, whereas if grammaticality is to be preserved, a large set of words belonging to the same syntactic category will usually be acceptable.
Stefflre has used distributional techniques to obtain measures of semantic similarity. He takes a particular word and asks people to generate a large number of sentences using it. Then he asks them to substitute another word for the original one in each of the sentences they have written. Taking the sentences as contexts and the whole set of substitutions as his set of words to be scaled, he creates a context-by¬word matrix, and has his subjects judge whether every context-word pair in the matrix is a plausible sentence. Then he can apply an intersection-union ratio to either the sets of contexts shared by two words, or to the sets of words admissible in two contexts.
In England Jones has proceeded along different lines toward a similar goal. She uses the Oxford English Dictionary to create a list of synonyms, or near-synonyms, for every word sense, then computes an intersection-union ratio for the number of shared synonyms.
(4) A number of workers have resorted to classification methods for particular purposes, but until recently there appears to have been no systematic use of these methods to explore semantic features. At present several variations of the general method are in use, but almost nothing of this work had appeared in print at the time this paper was written. In order to illustrate the classification method, therefore, I will describe a version of it that Herbert Rubenstein, Virginia Teller, and I have been using at Harvard.

In our method, the items to be classified are typed on file cards and a judge is asked to sort them into piles on the basis of similarity and meaning. He can form as many classes as he wants, and any number of items can be placed in each class. His classification is then recorded and summarized in a matrix, as indicated in Fig. 1, where data for three judges classifying eight words are given for illustrative purposes. A judge’s classification is tabulated in the matrix as if he had considered every pair independently and judged them to be either similar (tabulate 1) or dissimilar (tabulate o). For example, the first judge, S1 uses five classes to sort these eight words; he puts ‘cow’ and ‘tiger’ together, ‘chair’ and ‘rock’ together, and ‘fear’ and ‘virtue’ together, but leaves ‘tree’ and ‘mother’ as isolates. In the data matrix, therefore, this judge’s data contribute one tally in the cow-tiger cell, one in the chair-rock cell, and one in the fear-virtue cell. The data for the second and third judge are similarly scored, and the number of similarities indicated by their classifications are similarly tabulated in the matrix. Thus, in this example, all three subjects group the inanimate objects ‘chair’ and ‘rock’ together, so ‘3’ appears in that cell; two subjects group the animate organisms ‘cow’ and ‘mother’ together; etc. After the classifications of several judges are pooled in this manner, we obtain a data matrix that can be interpreted as a matrix of measures of semantic similarity: our assumption is that the more similar two items are, the more often people will agree in classifying them together. In our experience, judges can classify as many as 100 items at a time, and as few as 20 judges will generally suffice to give at least a rough indication of the pattern of similarities.
The data matrix is then analyzed by a procedure described and programmed for a computer by S. C. Johnson of the Bell Telephone Laboratories. The general principle of this cluster analysis is suggested in Fig. 2. If we look at the data matrix of Fig. 1 for those items that all three subjects put together, then we have the five classes shown at the tips of the tree in Fig. 2: (cow, tiger) (mother) (tree) (chair, rock) (fear, virtue).
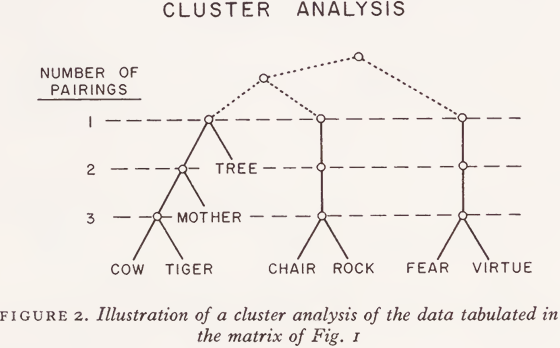
If we relax our definition of a cluster to mean that two or more judges agreed, we have only four classes; ‘mother’ joins with ‘cow’ and ‘tiger’ to form a single class. And when we further relax our definition of a cluster to include the judgment of only one person, we have only three classes: ‘ tree ’ joins ‘ mother ’, ‘ cow ’, and ‘ tiger ’. As Johnson points out, the level of the node connecting two branches can be interpreted as a measure of their similarity. The dotted lines at the top of Fig. 2 are meant to suggest that an object-nonobject dichotomy might have emerged with more data, but on the basis of the data collected, that must remain conjectural.
Our hope, of course, is that clusters obtained by this routine procedure will bear some resemblance to the kinds of taxonomic structures various theorists have proposed, and that the clusters and their branches can be labeled in such a way as to reflect the semantic markers or dimensions involved. Whether this hope is justified can be decided only by examining the results.
In order to illustrate the kind of results obtained with this classification procedure, consider a study whose results are summarized in Fig. 3. Forty-eight nouns were selected rather arbitrarily to cover a broad range of concepts, subject to the constraint that half of them should be names of objects and the other half should be names of nonobjects (concepts). This important semantic marker was introduced deliberately in order to see whether it would be detected by the clustering procedure; if so important a semantic marker would not come through clearly, then nothing would.
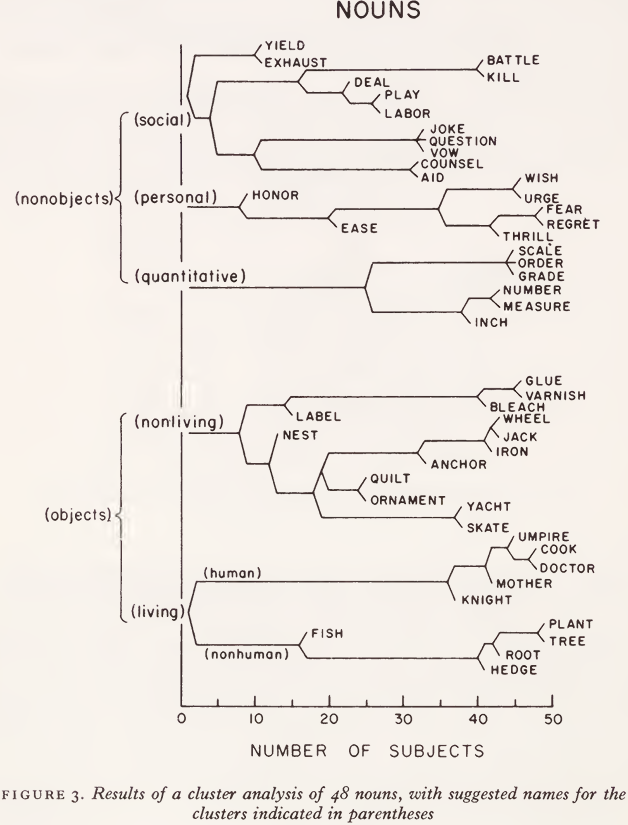
Each of the 48 nouns was typed on a 3" x 5" card, along with a dictionary definition of the particular sense of the word that was intended and a simple sentence using the word in that sense. The cards were classified by 50 judges, their results were tabulated in a data matrix, and cluster analysis was performed on the data matrix in order to determine what Johnson calls the optimally ‘compact’ set of clusters. The five major clusters that were obtained are shown in Fig. 3, where they are named, quite intuitively, ‘living objects’, and ‘nonliving objects’, ‘quantitative concepts’, ‘personal concepts’, and ‘social concepts’. The finer structure within each of these clusters is also diagrammed in Fig. 3. For example, the tree graph shows that 48 of the 50 judges put ‘plant’ and ‘tree’ into the same class; that 42 or more judges put ‘ plant ’, ‘ tree ’, and ‘ root ’ into the same class; and that 40 or more judges put ‘plant’, tree’, ‘root’, and ‘hedge’ into the same class.
Did the semantic marker that was deliberately introduced into the set of words reappear in the analysis? Yes and no. The clusters obtained did not contradict the hypothesis that our judges were sorting with this semantic distinction in mind, yet their data indicate a finer analysis into at least five, rather than only two clusters, so the object marker is not completely verified by these data. Nonetheless, the results were sufficiently encouraging that we continued to study the method.
The 48 nouns listed in Fig. 3 were also chosen to have the characteristic that each of them could also be used as a verb. In another study, therefore, the verb senses of these words were defined and illustrated on the cards that the judges were asked to classify. When they are thought of as verbs, of course, the object-concept distinction that is so obvious for these words in their noun usages is no longer relevant; the object marker would not be expected to appear in the results of the verb classifications, and in truth it did not. The results of the verb study are not presented here, however, because I do not yet understand them. The object marker did not appear, but neither did anything else that I could recognize. It is my impression that judges were too much influenced by other words in the particular sentences in which the verbs were illustrated. Perhaps the semantic analysis of predicates is basically different from the analysis of subjects; perhaps verbs signify rather special formulae - complex functions into which particular nouns can be substituted as arguments - and the classification of these functions is more complex, more contingent, more difficult than the classification of their arguments. This is a deep question which I am not prepared to discuss here.
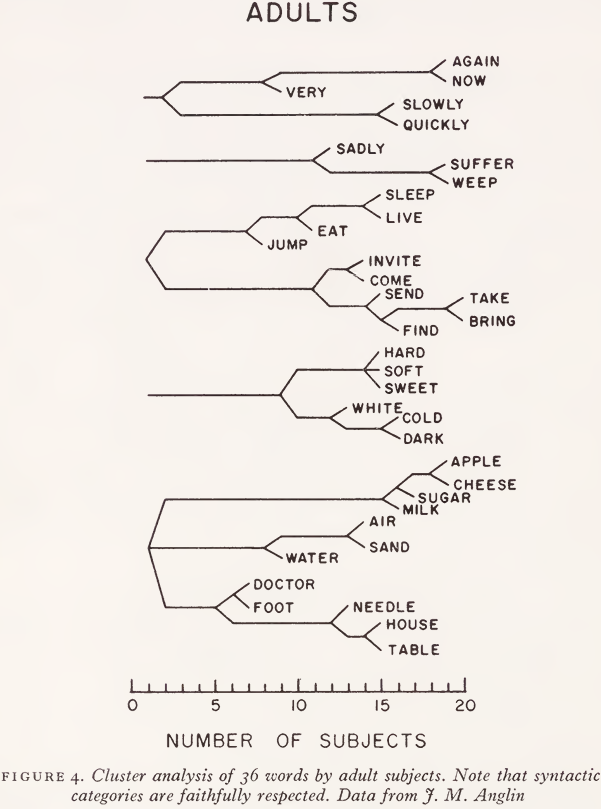
There is, of course, an important syntactic basis for classifying English words, i.e., the classification into parts of speech. The data in Fig. 3 were obtained for a single part of speech - nouns - and so do not give us any indication of the relative importance of syntactic categories. Fig. 4, however, shows some results obtained by Jeremy M. Anglin with a set of 36 common words consisting of twelve nouns, twelve verbs, six adjectives, and six adverbs. Twenty judges classified these concepts and the analysis of their data reveals five major clusters. Four of these clusters reflect the syntactic classification, but one - ‘ sadly ’, ‘ suffer ’, and ‘ weep ’ - combines an adverb with two verbs. With this one exception, however, adult judges seem to work by sorting the items on syntactic grounds before sorting them on semantic grounds.
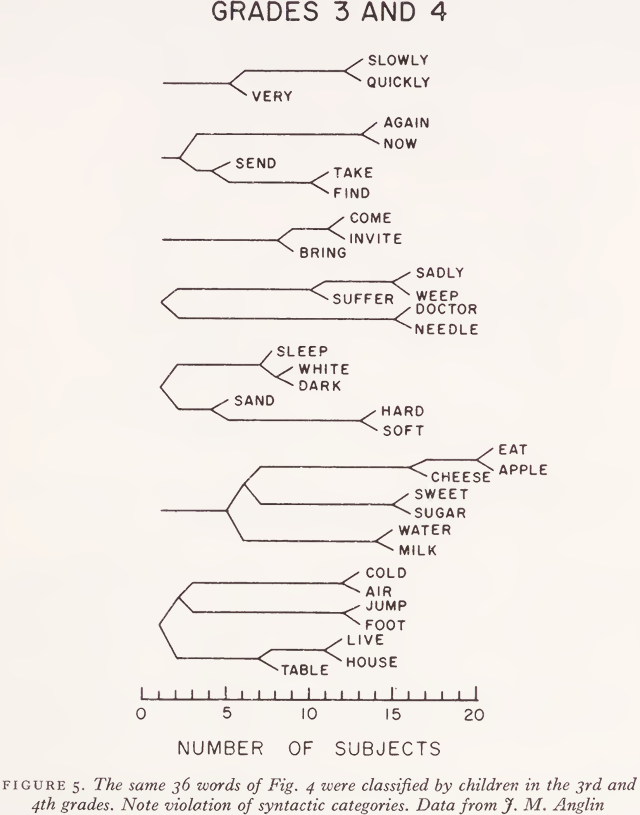
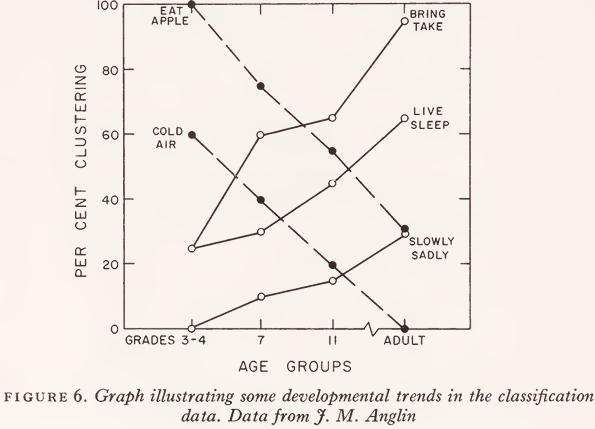
It is important to notice, however, that the results summarized in Fig. 4 were obtained with adult judges. Anglin also gave the same test to 20 subjects in the 3rd and 4th grades, to 20 in the 7th grade, and to 20 more in the nth grade (average ages about 8-5, 12, and 16 years, respectively). The clusters obtained from the youngest group of judges are shown in Fig. 5. It is obvious that children interpret the task quite differently. When asked to put things together that are similar in meaning, children tend to put together words that might be used in talking about the same thing - which cuts right across the tidy syntactic boundaries so important to adults. Thus all 20 of the children agree in putting the verb ‘ eat ’ with the noun ‘apple’; for many of them ‘air’ is ‘cold’; the ‘foot’ is used to ‘jump’; you ‘live’ in a ‘house’; ‘sugar’ is ‘sweet’; and the cluster of ‘doctor’, ‘needle’, ‘suffer’, ‘weep’, and ‘sadly’ is a small vignette in itself.
These qualitative differences observed in Anglin’s study serve to confirm develop-mental trends previously established on the basis of word association tests with children - an excellent discussion of this work has been given by Doris R. Entwisle - where it is found that children give more word association responses from different syntactic classes than do adults. This trend also appears in the classification data. In Fig. 6 some particular word pairs have been selected as illustrating most clearly the changes Anglin observed as a function of age. The thematic combination of words from different parts of speech, which is generally called a ‘ syntagmatic ’ response, can be seen to decline progressively with age, and the putting together of words in the same syntactic category, generally called a ‘paradigmatic’ response, increases during the same period.
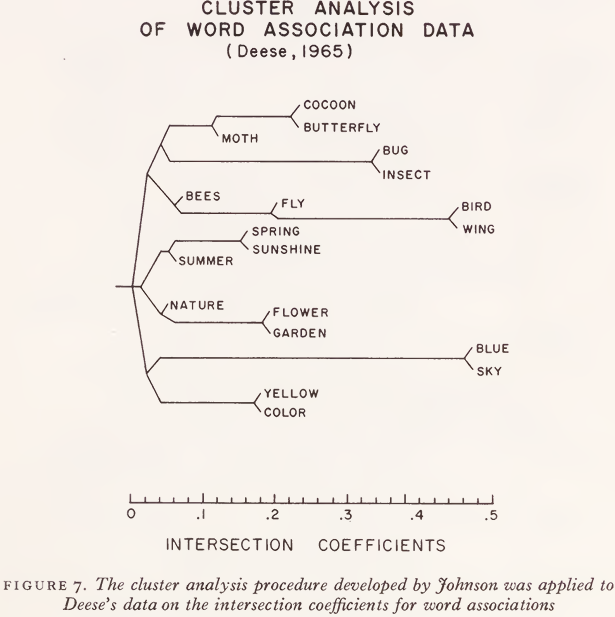
Although there is no basic contradiction between results obtained with word association methods and with word classification methods, some aspects of the subjective lexicon seem to be displayed more clearly with the classification procedures. In order to make some comparison between the two methods, we took word association data collected by Deese and used Johnson’s cluster analysis on them. In this particular study, Deese used the word ‘butterfly’ as a stimulus and obtained 18 different word associations from 50 undergraduates at Johns Hopkins. Then he used these 18 responses as stimuli for another group of 50 subjects. He then had response distributions for 19 closely related words, so that he was able to compute intersection coefficients (a particular version of an intersection-union ratio) between all of the 171 different pairs that can be formed from these 19 words. Deese published the intersection coefficients in a matrix whose entries could be interpreted as measures of associative similarity between words. When Johnson’s cluster analysis was carried out on this data matrix, the results showing in Fig. 7 were obtained.
The clusters obtained with the word association data are a bit difficult to interpret. If we ask whether these clusters preserve syntactic classes, the answer depends on whether we consider certain words to be nouns or adjectives. For example, ‘blue’ can be used either as an adjective (as in the phrase ‘blue sky’) or as a noun (as in the phrase ‘ sky blue ’); ‘ flower ’ would normally be considered as either a noun or a verb, but in ‘flower garden’ it functions as an adjective; ‘fly’ in the cluster with ‘ bird ’ and ‘ wing ’ is probably a verb; but it might be a noun; etc. One could also argue that many of the words have multiple meanings; for example, some of the subjects who associated ‘ spring ’ and ‘ sunshine ’ might have been thinking of ‘ spring ’ as a season of the year and others might have meant it as a source of water. In short, data of this sort are useful when words are to be dealt with in isolation, as they often are in verbal learning experiments, but they do not contribute the information we need in order to understand how word meanings work together in the interpretation of sentences.
For purposes of comparison, therefore, we appealed to a lexicographer: the 19 words in Deese’s study were looked up in a child’s dictionary, where a total of 72 different definitions were found. Each definition was typed onto a separate card, along with the word defined and a sentence illustrating its use. J. M. Anglin and Paul Bogrow tested 20 judges with these 72 items. Their results are shown in Fig. 8. Anglin and Bogrow found nine major clusters, which are quite different from Deese’s associative clusters and much closer to the requirements of a semantic theory. For example, there were twelve senses of ‘ spring’. Ten of these comprise a single cluster, and the similarity measure suggests how a lexical entry for these ten might be organized. ‘ Spring ’ in the sense of a source of water did not fit into this cluster, nor did ‘ spring ’ in the seasonal sense; those two senses would have to have separate entries. Whereas the preceding studies illustrated the use of the classification for widely different concepts, this one indicates that the method might also be useful for investigating the finer details of closely related meanings.
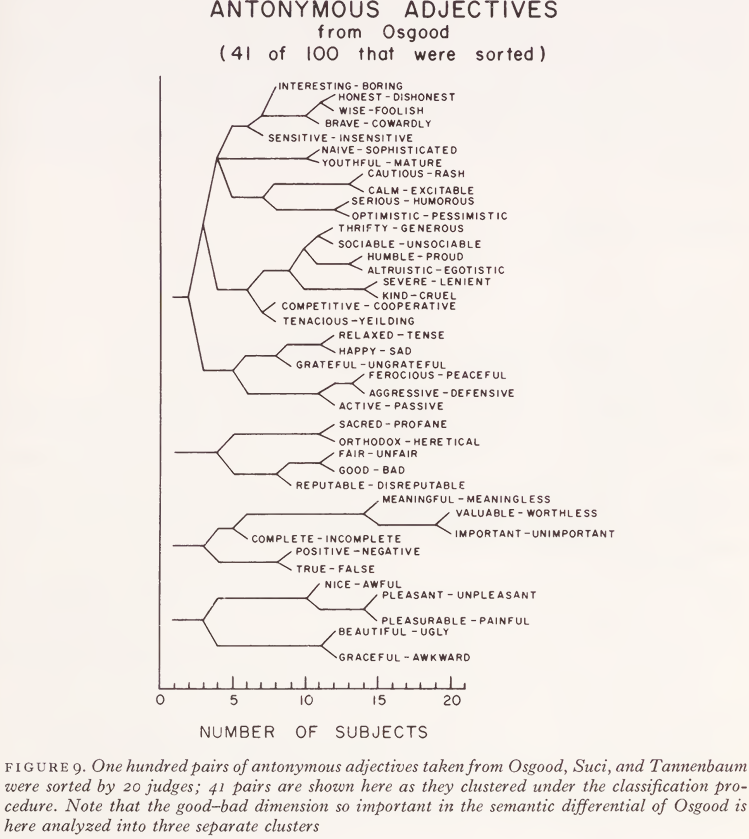
One final example of this method may be of interest. As mentioned previously, Osgood and his coworkers have made extensive use of rating scales defined by antonymous adjectives in order to define a coordinate system in which meanings can be characterized by their spatial position. We decided, therefore, to use antonymous pairs of adjectives in a classification study. One hundred of the adjective pairs Osgood had used were selected and typed on cards - this time without definitions or examples, since the antonymous relations left little room for ambiguity - and 20 judges were asked to classify them. The results for 41 of these 100 pairs are shown in Fig. 9 to illustrate what happened. (Data for the other 59 pairs is analogous, but limitations of space dictate their omission.)
Osgood finds rather consistently that the most important dimension in his semantic differential is the good-bad, or evaluative dimension. Most of the antonymous pairs that were heavily loaded on Osgood’s evaluative dimension turned up in our cluster analysis in the three clusters shown in the lower half of Fig. 9. Inspection of these three clusters suggests to me that our judges were distinguishing three different varieties of evaluation which, for lack of better terms might be called moral, intellectual, and esthetic. To the extent that Osgood’s method fails to distinguish among these varieties of evaluation, it must be lacking in differential sensitivity.
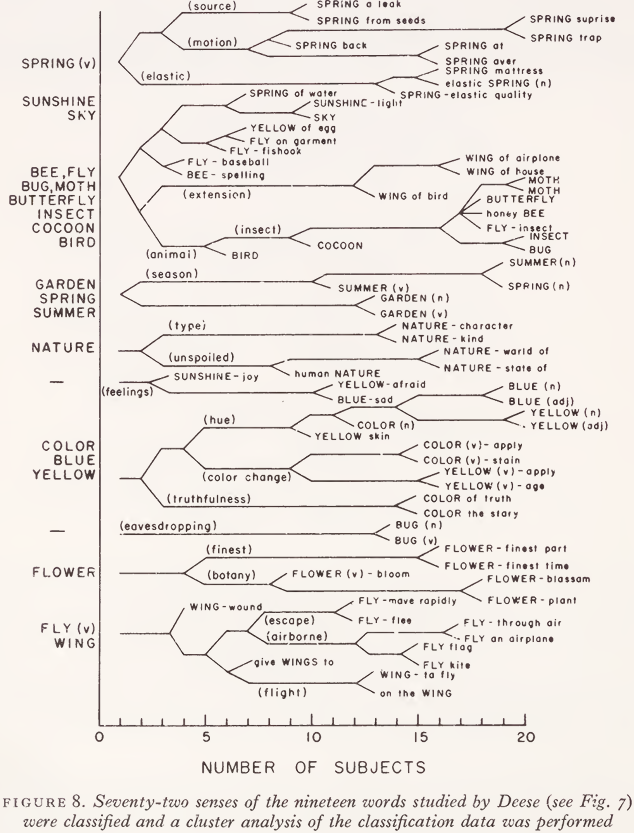
Fig. 9 also presents a large cluster of adjectives that, according to the introspective reports of some judges, might be considered as going together because ‘they can all be used to describe people’. It is not easy to know what this characterization means, since almost any adjective can be used to describe someone, but perhaps it points in a suggestive direction. It should be noted, however, that this characterization is not given in terms of similarities of meanings among the adjectives, but rather in terms of similarities among the words they can modify. Once again, therefore, we stumble over this notion that the nouns may have a relatively stable semantic character, but the words that go with them, the adjectives and verbs, are much more dependent on context for their classification.
There are still difficulties that must be overcome before the classification method can be generally useful. Some way must be found to work with more than 100 meanings at a time. Some way should be sought to locate generic words at branching points. Effects of context - both of the sentence in which the meaning is exemplified, and also of the context provided by the other words in the set to be classified - must be evaluated. Relations of cluster analysis to factor analysis need to be better understood, and so on and on down a catalogue of chores. But the general impression we have formed after using the classification method is that, while it is certainly not perfect, it seems to offer more promise for semantic theory than any of the other techniques psychologists have used to probe the structure of the subjective lexicon.
1 This paper is reprinted from D. L. Arm (ed.), Journeys in Science: Small Steps - Great Strides, Albuquerque: University of New Mexico Press, 1967, pp. 51-73.
 الاكثر قراءة في Semantics
الاكثر قراءة في Semantics
 اخر الاخبار
اخر الاخبار
اخبار العتبة العباسية المقدسة

الآخبار الصحية


مواضيع ذات صلة
 قسم الشؤون الفكرية يصدر كتاباً يوثق تاريخ السدانة في العتبة العباسية المقدسة
قسم الشؤون الفكرية يصدر كتاباً يوثق تاريخ السدانة في العتبة العباسية المقدسة "المهمة".. إصدار قصصي يوثّق القصص الفائزة في مسابقة فتوى الدفاع المقدسة للقصة القصيرة
"المهمة".. إصدار قصصي يوثّق القصص الفائزة في مسابقة فتوى الدفاع المقدسة للقصة القصيرة (نوافذ).. إصدار أدبي يوثق القصص الفائزة في مسابقة الإمام العسكري (عليه السلام)
(نوافذ).. إصدار أدبي يوثق القصص الفائزة في مسابقة الإمام العسكري (عليه السلام)